
nfs高可用架构之DRBD+heartbeat
一:软件简介
Heartbeat介绍
官方站点:http://linux-ha.org/wiki/Main_Page
heartbeat可以资源(VIP地址及程序服务)从一台有故障的服务器快速的转移到另一台正常的服务器提供服务,heartbeat和keepalived相似,heartbeat可以实现failover功能,但不能实现对后端的健康检查
heartbeat和keepalived应用场景及区别
很多网友说为什么不使用keepalived而使用长期不更新的heartbeat,下面说一下它们之间的应用场景及区别
1、对于web,db,负载均衡(lvs,haproxy,nginx)等,heartbeat和keepalived都可以实现
2、lvs最好和keepalived结合,因为keepalived最初就是为lvs产生的,(heartbeat没有对RS的健康检查功能,heartbeat可以通过ldircetord来进行健康检查的功能)
3、mysql双主多从,NFS/MFS存储,他们的特点是需要数据同步,这样的业务最好使用heartbeat,因为heartbeat有自带的drbd脚本
总结:无数据同步的应用程序高可用可选择keepalived,有数据同步的应用程序高可用可选择heartbeat
DRBD介绍
官方站点:http://www.drbd.org/
DRBD(DistributedReplicatedBlockDevice)是一个基于块设备级别在远程服务器直接同步和镜像数据的软件,用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。它可以实现在网络中两台服务器之间基于块设备级别的实时镜像或同步复制(两台服务器都写入成功)/异步复制(本地服务器写入成功),相当于网络的RAID1,由于是基于块设备(磁盘,LVM逻辑卷),在文件系统的底层,所以数据复制要比cp命令更快
DRBD已经被MySQL官方写入文档手册作为推荐的高可用的方案之一
nfs介绍
NFS(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
二:架构基本环境准备
1.本次实验架构图如下:

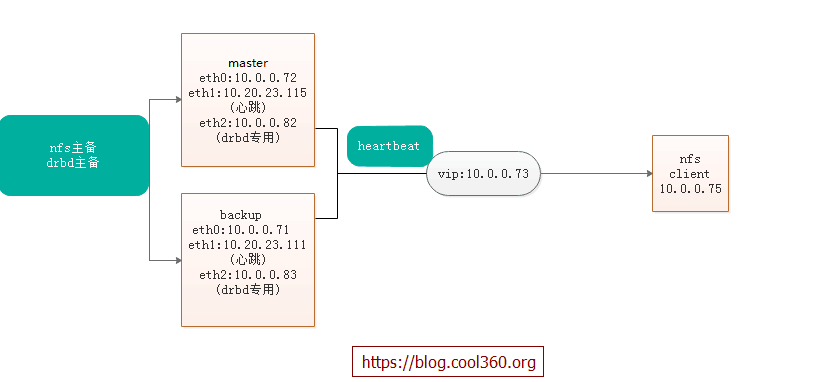
nfs高可用架构
2.实验基础环境:
[root@backup ~]# cat /etc/hosts 10.0.0.72 master 10.0.0.71 backup [root@backup ~]# uname -a Linux backup 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux [root@master ~]# uname -a Linux master 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux [root@master ~]# /etc/init.d/iptables stop [root@backup ~]# /etc/init.d/iptables stop [root@backup ~]# setenforce 0 [root@master ~]# setenforce 0 or sed -i 's/SELINUX=enforcing/SELINUX=disabled' /etc/selinux/config
时间同步:
[root@master ~]# ntpdate 10.0.2.2 29 Aug 09:26:22 ntpdate[2288]: step time server 10.0.2.2 offset -28524.389257 sec [root@backup ~]# ntpdate 10.0.2.2 29 Aug 09:26:55 ntpdate[2255]: step time server 10.0.2.2 offset 13332955.402534 sec
添加路由心跳线:
master: route add -host 10.20.23.111 dev eth2 echo "/sbin/route add -host 10.20.23.111 dev eth2" >>/ect/rc.local backup route add -host 10.20.23.115 dev eth2 echo "/sbin/route add -host 10.20.23.115 dev eth2" >>/ect/rc.local
三.配置heartbeat
1.安装heartbeat
wget http://mirrors.sohu.com/fedora-epel/6/i386/epel-release-6-8.noarch.rpm rpm -ivh epel-release-6-8.noarch.rpm yum install heartbeat* 查看安装版本: [root@backup ~]# rpm -qa heartbeat heartbeat-3.0.4-2.el6.x86_64 [root@master ~]# rpm -qa heartbeat heartbeat-3.0.4-2.el6.x86_64
2.配置文件
ha.cf heartbeat参数配置文件
authkey heartbeat认证文件
haresource 资源配置文件
模板配置文件:
[root@master ha.d]# ll /usr/share/doc/heartbeat-3.0.4/ -rw-r--r--. 1 root root 1873 Dec 2 2013 apphbd.cf -rw-r--r--. 1 root root 645 Dec 2 2013 authkeys -rw-r--r--. 1 root root 3701 Dec 2 2013 AUTHORS -rw-r--r--. 1 root root 58752 Dec 2 2013 ChangeLog -rw-r--r--. 1 root root 17989 Dec 2 2013 COPYING -rw-r--r--. 1 root root 26532 Dec 2 2013 COPYING.LGPL -rw-r--r--. 1 root root 10502 Dec 2 2013 ha.cf -rw-r--r--. 1 root root 5905 Dec 2 2013 haresources -rw-r--r--. 1 root root 2935 Dec 2 2013 README cd /etc/ha.d [root@master ha.d]# cp /usr/share/doc/heartbeat-3.0.4/ha.cf ./ [root@master ha.d]# cp /usr/share/doc/heartbeat-3.0.4/authkeys ./ [root@master ha.d]# cp /usr/share/doc/heartbeat-3.0.4/haresources ./
赋权限:
chmod 600 /etc/ha.d/authkeys
修改配置文件:
[root@master ha.d]# cp ha.cf{,.bak}
[root@master ha.d]# cp authkeys{,.bak}
[root@master ha.d]# cp haresources{,.bak}
cat >/etc/ha.d/ha.cf<<EOF
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0
keepalive 2
deadtime 30
warntime 10
initdead 60
mcast eth1 225.0.0.1 694 1 0
auto_failback on
node master
node backup
EOF
[root@master ha.d]# grep -Ev '#|^$' /etc/ha.d/ha.cf
cat >/etc/ha.d/authkeys <<EOF
auth 1
1 sha1 c4f9375f9834b4e7f0a528cc65c055702bf5f24a
EOF
chmod 600 /etc/ha.d/authkeys
ll /etc/ha.d/authkeys
grep -Ev '#|^$' /etc/ha.d/authkeys
cat >/etc/ha.d/haresources<<EOF
master IPaddr::10.0.0.73/25/eth0
EOF
3.启动主的heartbeat
[root@master network-scripts]# /etc/init.d/heartbeat start
查看vip开启情况:
开始的时候没发现VIP 60s后vip绑定原因是initdead 60;
[root@master network-scripts]# ip add|grep 10.0.0.
inet 10.0.0.72/25 brd 10.0.0.127 scope global eth0
inet 10.0.0.73/25 brd 10.0.0.127 scope global secondary eth0
[root@backup ~]# ip addr |grep 10.0.0
inet 10.0.0.71/25 brd 10.0.0.127 scope global eth0
4.测试heartbeat
停掉masterheartbeat,查看是否接管。
[root@master ha.d]# /etc/init.d/heartbeat stop Stopping High-Availability services: Done.
查看backup是否接管;基本很快接管。

5.测试专用:
释放heartbeat到另一台
/usr/share/heartbeat/hb_standby
接管回来:
/usr/share/heartbeat/hb_takeover
四:配置drbd
1.主备各添加一块磁盘,2G,3G。
2.对新磁盘进行分区
[root@master ~]# fdisk -l Disk /dev/sdb: 2147 MB, 2147483648 bytes 255 heads, 63 sectors/track, 261 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000 [root@backup ~]# fdisk -l Disk /dev/sdb: 3221 MB, 3221225472 bytes 255 heads, 63 sectors/track, 391 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000 备注:16T以上可以使用e2fsprogs进行格式化,或者改成xfs格式 大于2T分区格式化:parted master,backup都要操作: master: [root@master ~]# yum install -y parted [root@master ~]# parted /dev/sdb mklabel gpt yes ##调整分区表 Warning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do you want to continue? Information: You may need to update /etc/fstab. [root@master ~]# parted /dev/sdb mkpart primary ext4 0 1000 ignore #增加一个分区 Warning: The resulting partition is not properly aligned for best performance. Information: You may need to update /etc/fstab. [root@master ~]# parted /dev/sdb mkpart primary ext4 1001 2000 Yes ignore #增加一个分区 Warning: You requested a partition from 1001MB to 2000MB. The closest location we can manage is 1001MB to 1001MB. Is this still acceptable to you? Warning: The resulting partition is not properly aligned for best performance. Information: You may need to update /etc/fstab. [root@master ~]# parted /dev/sdb p #查看分区结果 Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 2147MB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 17.4kB 1000MB 1000MB primary 2 1001MB 2000MB 998MB primary [root@master ~]# ls /dev/sdb* /dev/sdb /dev/sdb1 /dev/sdb2
3.格式化分区:
meta data分区无需格式化
[root@master ~]# mkfs.ext4 /dev/sdb1 [root@master ~]# tune2fs -c -1 /dev/sdb1 #取消磁盘检查 tune2fs 1.41.12 (17-May-2010) Setting maximal mount count to -1 [root@backup ~]# mkfs.ext4 /dev/sdb1 [root@backup ~]# tune2fs -c -1 /dev/sdb1 tune2fs 1.41.12 (17-May-2010) Setting maximal mount count to -1
4.安装DRBD软件:
master,backup都安装drbd
rpm -Uvh http://www.elrepo.org/elrepo-release-6-8.el6.elrepo.noarch.rpm yum install drbd kmod-drbd84 -y [root@master src]# rpm -qa drbd84-utils kmod-drbd84 drbd84-utils-8.9.8-1.el6.elrepo.x86_64 kmod-drbd84-8.4.9-1.el6.elrepo.x86_64 [root@backup ~]# rpm -qa drbd84-utils kmod-drbd84 drbd84-utils-8.9.8-1.el6.elrepo.x86_64 kmod-drbd84-8.4.9-1.el6.elrepo.x86_64
加载到内核中:
master: [root@master ~]# lsmod | grep drbd [root@master ~]# modprobe drbd [root@master ~]# lsmod | grep drbd drbd 374888 0 libcrc32c 1246 1 drbd backup: [root@backup ~]# lsmod | grep drbd [root@backup ~]# modprobe drbd [root@backup ~]# lsmod | grep drbd drbd 374888 0 libcrc32c 1246 1 drbd echo "modprobe drbd" >>/etc/rc.local or echo "modprobe drbd" >/etc/sysconfig/modules/drbd.modules #加载到内核模块中 chmod 755 /etc/sysconfig/modules/drbd.modules
5:编辑drbd.conf
global {
usage-count no; ##是否参加DRBD使用者统计,默认是yes
}
common { ##通用配置
syncer {
rate 100M; ##设置主备节点同步时的网络速率最大值
verify-alg crc32c;
}
}
# primary for drbd1
resource data { ##data是资源名字
protocol C; ##协议
disk { ##磁盘错误控制
on-io-error detach; ##分离
}
on master { ##节点hostname
device /dev/drbd0;
disk /dev/sdb1; ##drbd0对应的磁盘
address 10.0.0.82:7788; ##通讯监听地址,心跳IP
meta-disk /dev/sdb2[0]; ##存放meta信息
}
on backup {
device /dev/drbd0;
disk /dev/sdb1;
address 10.0.0.83:7788;
meta-disk /dev/sdb2[0];
}
}
6.master,backup一起执行,初始化drbd
[root@master etc]# drbdadm create-md data
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created.
[root@backup ~]# drbdadm create-md data
启动drbd:
drbdadm up all
or
/etc/init.d/drbd start
执行结果输出:
Starting DRBD resources: [
create res: data
prepare disk: data
adjust disk: data
adjust net: data
]
查看启动状态:
cat /proc/drbd
or
/etc/init.d/drbd status
[root@master etc]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.4.9-1 (api:1/proto:86-101)
GIT-hash: 9976da086367a2476503ef7f6b13d4567327a280 build by mockbuild@Build64R6, 2016-12-13 18:38:15
m:res cs ro ds p mounted fstype
0:data Connected Secondary/Secondary Inconsistent/Inconsistent C
[root@backup ~]# cat /proc/drbd
version: 8.4.9-1 (api:1/proto:86-101)
GIT-hash: 9976da086367a2476503ef7f6b13d4567327a280 build by mockbuild@Build64R6, 2016-12-13 18:38:15
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:976548

7.master提升为主:
在master执行
drbdadm -- --overwrite-data-of-peer primary data
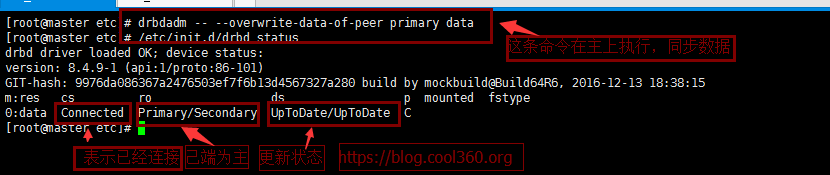
查看备节点:

8.挂载drbd
root@master etc]# mkdir /data -p
[root@master etc]# mount /dev/drbd0 /data
查看挂载情况

五.配置nfs
1.安装nfs
[root@master ~]# yum install -y rpcbind nfs-utils [root@backup data]# yum install -y rpcbind nfs-utils
2.配置nfs共享目录
[root@master ~]# cat /etc/exports ####nfs+drbd+heartbeat /data 10.0.0.0/24(rw,sync,all_squash) [root@backup data]# cat /etc/exports ####nfs+drbd+heartbeat /data 10.0.0.0/24(rw,sync,all_squash) 参考标准: [root@M1 drbd]# cat /etc/exports /data 192.168.0.0/24(rw,sync,no_root_squash,anonuid=0,anongid=0) [root@M2 ~]# cat /etc/exports /data 192.168.0.0/24(rw,sync,no_root_squash,anonuid=0,anongid=0)
3.启动rpcbind和nfs服务
[root@master ~]# /etc/init.d/rpcbind start;chkconfig rpcbind off
[root@master ~]# /etc/init.d/nfs start;chkconfig nfs off
Starting NFS services: [ OK ]
Starting NFS quotas: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
Starting RPC idmapd: [ OK ]
[root@backup data]# /etc/init.d/rpcbind start;chkconfig rpcbind off
[root@backup data]# /etc/init.d/nfs start;chkconfig nfs off
Starting NFS services: [ OK ]
Starting NFS quotas: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
Starting RPC idmapd: [ OK ]
[root@backup data]# rpcinfo -p 127.0.0.1
program vers proto port service
100000 4 tcp 111 portmapper
100000 3 tcp 111 portmapper
100000 2 tcp 111 portmapper
100000 4 udp 111 portmapper
4.测试nfs
[root@master ~]# showmount -e 10.0.0.72 Export list for 10.0.0.72: /data 10.0.0.0/24 [root@backup data]# showmount -e 10.0.0.71 Export list for 10.0.0.71: /data 10.0.0.0/24 说明nfs已经搭建成功。 挂载到其他服务器测试: [root@sf75 ~]# mount -t nfs 10.0.0.72:/data /data/data1 [root@sf75 ~]# mount -t nfs 10.0.0.71:/data /data/data2 [root@sf75 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 8.5G 2.5G 6.0G 30% / devtmpfs 481M 0 481M 0% /dev tmpfs 490M 0 490M 0% /dev/shm tmpfs 490M 6.7M 484M 2% /run tmpfs 490M 0 490M 0% /sys/fs/cgroup /dev/sda1 497M 120M 378M 25% /boot tmpfs 98M 0 98M 0% /run/user/0 10.0.0.72:/data 923M 1.2M 874M 1% /data/data1 10.0.0.71:/data 8.4G 2.2G 5.8G 28% /data/data2
六、整合Heartbeat、DRBD和NFS服务
关于heartbeat的修改两台都要修改,保持一致。
1.修改heartbeat配置文件haresources
master drbddisk::data Filesystem::/dev/drbd0::/data::ext4 nfsd IPaddr::10.0.0.73/25/eth0
2.heartbeat默认没有关于nfs的脚本,我们要自己写一个
#!/bin/bash
case $1 in
start)
/etc/init.d/nfs restart
;;
stop)
for proc in rpc.mountd rpc.rquotad nfsd nfsd
do
killall -9 $proc
done
;;
esac
添加执行权限:
chmod +x /etc/ha.d/resource.d/nfsd
3.测试nfs高可用
[root@master ha.d]# /etc/init.d/heartbeat stop [root@backup ha.d]# /etc/init.d/heartbeat stop [root@master ha.d]# /etc/init.d/heartbeat start Starting High-Availability services: INFO: Resource is stopped Done. [root@backup ha.d]# /etc/init.d/heartbeat start Starting High-Availability services: INFO: Resource is stopped Done.
master各种状态:
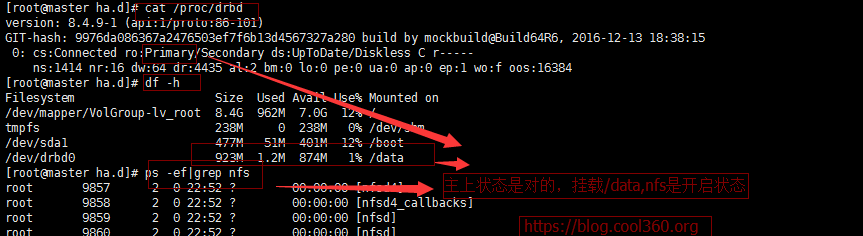
backup各种状态:
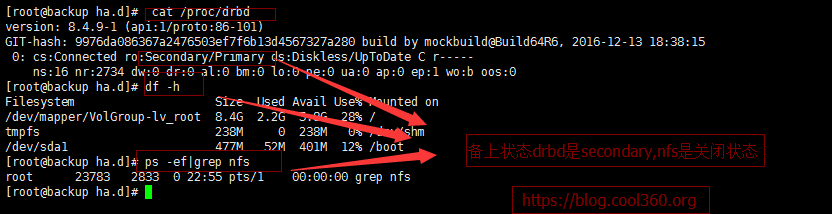
查看客户端挂载情况

正常可用。
现在停掉主上的heartbeat,模拟down机状态:
[root@master ha.d]# /etc/init.d/heartbeat stop Stopping High-Availability services: Done.
查看备上各种状态:
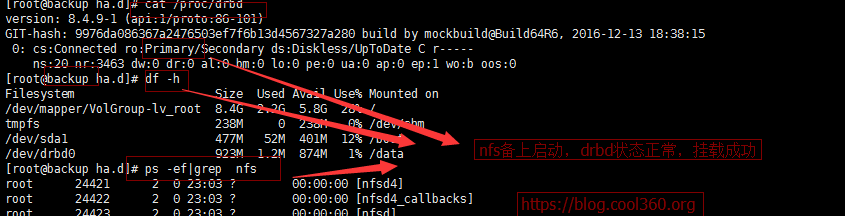
状态是正常的。
查看client能否正常写入:
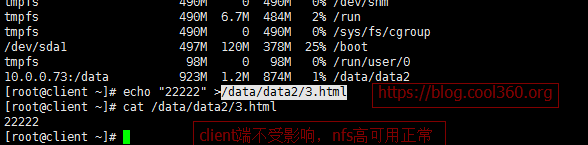
启动主上heartbeat:
[root@master ha.d]# /etc/init.d/heartbeat start Starting High-Availability services: INFO: Resource is stopped Done.
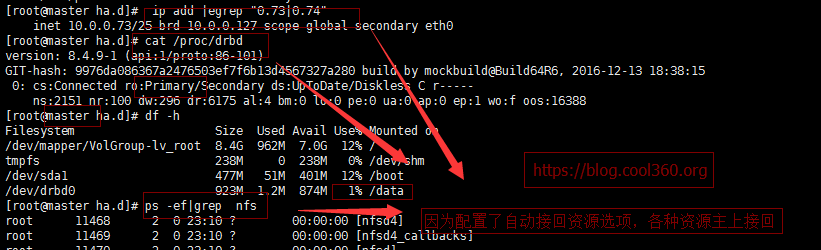
本次实验到此结束。
这货来去如风,什么鬼都没留下!!!












嗨、骚年、快来消灭0回复。